
深度学习知识总结-过拟合、欠拟合和正则化
深度学习知识总结-过拟合、欠拟合和正则化
在深度学习(机器学习)领域,训练模型时,我们不仅要求模型对训练数据集有很好的拟合(较低的训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。其中就会产生欠拟合和过拟合的问题。
一. 欠拟合
什么是欠拟合
欠拟合是指模型在训练集上的表现很差,训练误差高。我们需要模型尽可能地学习到给定数据集的特征,从而拟合数据分布,而欠拟合即模型在拟合训练集时,效果并不好,没有学习到数据分布的规律。造成欠拟合的原因,一般是模型的复杂度较低,模型在训练集中的表现都不够好。
如何解决欠拟合问题
在模型刚开始训练时,一般存在欠拟合的问题,在经过不断的训练之后,会一定程度改善欠拟合的程度。但是,如果在经过足够的训练后,还存在欠拟合的问题,可以通过增加网络的复杂度和增加特征来解决欠拟合的问题。
二. 过拟合
什么是过拟合
过拟合是指模型在训练集中有很好的表现,但是在测试集中误差大,两者误差差距大。也即模型的复杂度高于实际需要解决的问题,模型在训练集上表现很好,但在测试集上却表现很差。可以理解为,模型直接将训练集的数据特征死记硬背,无法做到举一反三,在新的数据中表现很差,对训练集“过解读”,泛化能力差。
以下图可以很好的解释欠拟合,过拟合的效果:
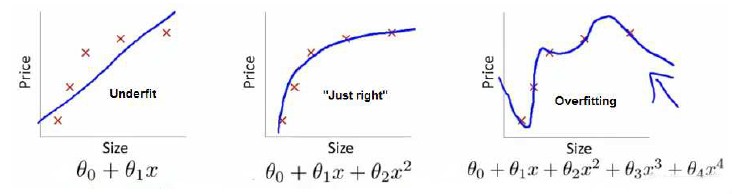
图中,图一为欠拟合现象,模型对训练数据的拟合能力不够,图二为正常拟合,图三为过拟合现象,即模型存在对训练数据“过度解读”。
为什么会出现过拟合现象
造成过拟合的原因主要有以下几种:
- 训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
- 训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,忽略了真实输入和输出之间的关系。
- **模型过于复杂。**模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
如何防止过拟合
要想解决过拟合问题,就要显著减少测试误差而不过度增加训练误差,从而提高模型的泛化能力。可以使用正则化(Regularization)方法解决模型过拟合问题。
常用的正则化方法根据具体的使用策略不同可分为:
(1)直接提供正则化约束的参数正则化方法,如L1/L2正则化;
(2)通过工程上的技巧来实现更低泛化误差的方法,如提前终止(Early stopping)和Dropout;
(3)不直接提供约束的隐式正则化方法,如数据增强等。
1. 获取和使用更多的数据(数据集增强)
让机器学习或深度学习模型泛化能力更好的办法就是使用更多的数据进行训练。但是,在实践中,我们拥有的数据量是有限的。解决这个问题的一种方法就是创建“假数据”并添加到训练集中——数据集增强。通过增加训练集的额外副本来增加训练集的大小,进而改进模型的泛化能力。
2. 采用合适的模型(控制模型的复杂度)
过于复杂的模型会带来过拟合问题。对于模型的设计,目前公认的一个深度学习规律"deeper is better"。国内外各种大牛通过实验和竞赛发现,对于CNN来说,层数越多效果越好,但是也更容易产生过拟合,并且计算所耗费的时间也越长。
3. 降低特征的数量
对于一些特征工程而言,可以降低特征的数量——删除冗余特征,人工选择保留哪些特征。这种方法也可以解决过拟合问题。
4. L1 / L2 正则化
(1) L1 正则化
在原始的损失函数后面加上一个L1正则化项,即全部权重
求导为:
其中:
梯度下降时,权重
当
当
当
所以,L1正则化使得权重
这也就是L1正则化会产生更稀疏(sparse)的解的原因。此处稀疏性指的是最优值中的一些参数为0。L1正则化的稀疏性质已经被广泛地应用于特征选择机制,从可用的特征子集中选择出有意义的特征。
(1) L2 正则化
L2正则化通常被称为权重衰减(weight decay),就是在原始的损失函数后面再加上一个L2正则化项,即全部权重
对应的导数为:
权重更新:
这里,
5. Dropout
Dropout是在训练网络时用的一种trick,相当于在隐藏单元增加了噪声。Dropout 指的是在训练过程中每次按一定的概率(比如50%)随机地“删除”一部分隐藏单元(神经元)。所谓的“删除”不是真正意义上的删除,其实就是将该部分神经元的激活函数设为0(激活函数的输出为0),让这些神经元不计算而已。
如下图:(图片来自Dropout论文)
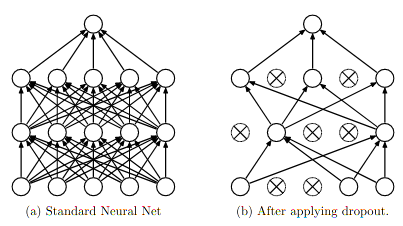
Dropout为什么有助于防止过拟合呢?
(a)在训练过程中会产生不同的训练模型,不同的训练模型也会产生不同的的计算结果。随着训练的不断进行,计算结果会在一个范围内波动,但是均值却不会有很大变化,因此可以把最终的训练结果看作是不同模型的平均输出。
(b)它消除或者减弱了神经元节点间的联合,降低了网络对单个神经元的依赖,从而增强了泛化能力。
6. 提前终止训练(Early Stopping)
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)。Early stopping是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
为了获得性能良好的神经网络,训练过程中可能会经过很多次epoch(遍历整个数据集的次数,一次为一个epoch)。如果epoch数量太少,网络有可能发生欠拟合;如果epoch数量太多,则有可能发生过拟合。Early stopping旨在解决epoch数量需要手动设置的问题。具体做法:每个epoch(或每N个epoch)结束后,在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练,将停止之后的权重作为网络的最终参数。
**为什么能防止过拟合?**当还未在神经网络运行太多迭代过程的时候,w参数接近于0,因为随机初始化w值的时候,它的值是较小的随机值。当你开始迭代过程,w的值会变得越来越大。到后面时,w的值已经变得十分大了。所以early stopping要做的就是在中间点停止迭代过程。我们将会得到一个中等大小的w参数,会得到与L2正则化相似的结果,选择了w参数较小的神经网络。
Early Stopping缺点:没有采取不同的方式来解决优化损失函数和过拟合这两个问题,而是用一种方法同时解决两个问题 ,结果就是要考虑的东西变得更复杂。之所以不能独立地处理,因为如果你停止了优化损失函数,你可能会发现损失函数的值不够小,同时你又不希望过拟合。