Yolov5 TensorRT推理加速(c++版)
Yolov5 TensorRT推理加速(c++版)
Yolov5 不做赘述,目前目标检测里使用非常多的模型,效果和速度兼顾,性能强悍,配合TensorRT推理加速,在工业界可以说是非常流行的组合。
废话不多说,直接开整,以下使用的Tensor RT部署推理路线为:Pytorch-> ONNX -> TensorRT。
pytorch导出到onnx模型,可以非常方便,并且支持dynamic维度,配合netron工具,可以查看模型的网络结构,而TensorRT对ONNX的支持也非常完整,所以选择这一套流程,可以非常轻松的完成TensorRT的部署,同时,tensor RT提供官方的nms插件,使得推理代码可以免去编写nms的部分,极大提高效率。
环境准备
- 系统:Ubuntu20.04LTS系统,或者tensorRT官方docker镜像:nvcr.io/nvidia/tensorrt:21.05-py3(推荐)
- TensorRT: 本篇使用的TensorRT7.2.3
- Yolov5: 截止2021.09.11的develop分支代码
- gcc: 9.3.0
- torch: 1.8.2
- onnx:1.10.1
- onnx-simplifier:0.3.6
pytorch模型训练
clone Yolov5的官方代码,按照教程训练得到pt权重文件。
github地址:
https://github.com/ultralytics/yolov5Torch -> onnx
在导出到onnx之前,为了方便后续添加nms插件,需要对torch的模型输出做一些修改.
models/yolo.py:
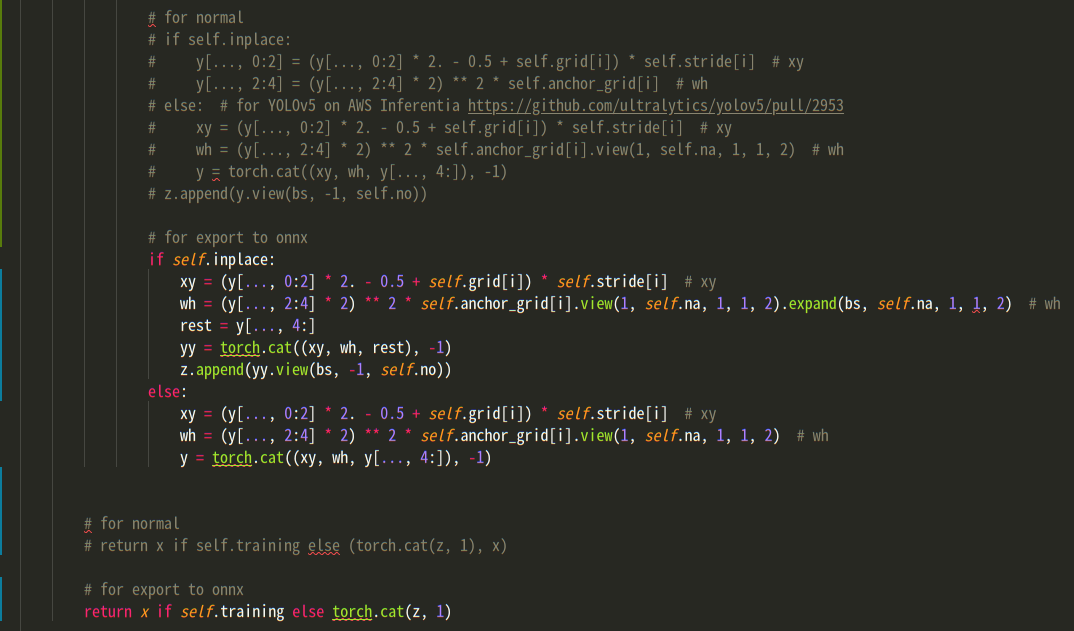
将这部分代码
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))替换为:
if self.inplace:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2).expand(bs, self.na, 1, 1, 2) # wh
rest = y[..., 4:]
yy = torch.cat((xy, wh, rest), -1)
z.append(yy.view(bs, -1, self.no))
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)同时,这句:
return x if self.training else (torch.cat(z, 1), x)替换为:
return x if self.training else torch.cat(z, 1)最后如图所示:
models/export.py
改写后,官方的export.py已不适用,使用以下export代码:
'''
export yolov5 .pt model to onnx model
Usage:
python models/export.py --weights yolov5s.pt --img-size 640 \
--batch-size 1 --device 0 --include onnx --inplace --dynamic \
--simplify --opset-version 11 --img test_img/1.jpg
'''
import argparse
import sys
import time
from pathlib import Path
sys.path.append(Path(__file__).parent.parent.absolute().__str__()) # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
from torch.utils.mobile_optimizer import optimize_for_mobile
import models
from models.experimental import attempt_load
from utils.activations import Hardswish, SiLU
from utils.general import colorstr, check_img_size, check_requirements, file_size, set_logging
from utils.torch_utils import select_device
def xywh2xyxy(x):
center = x[:, :, :2]
wh = x[:, :, 2:] / 2.
return torch.cat([center - wh, center + wh], -1)
class Yolov5(nn.Module):
def __init__(self, opt):
super().__init__()
self.model = self.init_model(opt)
def init_model(self, opt):
# load PyTorch model
model = attempt_load(opt.weights)
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6 compatbility
if isinstance(m, models.common.Conv):
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, models.yolo.Detect):
m.inplace = opt.inplace
m.onnx_dynamic = opt.dynamic
return model
def forward(self, x):
output = self.model(x)
output = self.post_processing(output)
return output
def post_processing(self, x):
bs, nb_box, infos = x.shape
boxes_input = xywh2xyxy(x[..., :4]).reshape(bs, nb_box, 1, 4)
scores_input = x[..., 5:] * x[..., 4:5]
return [boxes_input, scores_input]
def remove_initializer_from_input(model):
if model.ir_version < 4:
print(
'Model with ir_version below 4'
)
return
inputs = model.graph.input
name_to_input = {}
for input in inputs:
name_to_input[input.name] = input
for initializer in model.graph.initializer:
if initializer.name in name_to_input:
inputs.remove(name_to_input[initializer.name])
return model
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
def preprocess_image(image_raw, INPUT_W=640, INPUT_H=640):
h, w, c = image_raw.shape
image = image_raw.copy()
r_w = INPUT_W / w
r_h = INPUT_H / h
if r_h > r_w:
tw = INPUT_W
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((INPUT_H - th) / 2)
ty2 = INPUT_H - th - ty1
else:
tw = int(r_h * w)
th = INPUT_H
tx1 = int((INPUT_W - tw) / 2)
tx2 = INPUT_W - tw - tx1
ty1 = ty2 = 0
image = cv2.resize(image, (tw, th))
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, (128, 128, 128)
)
return image
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolov5s.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--include', nargs='+', default=['torchscript', 'onnx', 'coreml'], help='include format')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set Yolov5 Detect() inplace=True')
parser.add_argument('--train', action='store_true', help='model.train() mode')
parser.add_argument('--optimize', action='store_true', help='optimize TorchScript for mobile') # TorchScript-only
parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
parser.add_argument('--simplify', action='store_true', help='simplify ONNX model')
parser.add_argument('--opset-version', type=int, default=11, help='ONNX opset version')
parser.add_argument('--img', type=str, default='', help='test image path')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1
opt.img_size = (640, 640)
opt.include = [x.lower() for x in opt.include]
print(opt)
set_logging()
t = time.time()
device = select_device(opt.device)
import cv2
image_path = opt.img
image = cv2.imread(image_path)
from utils.datasets import letterbox
frame = preprocess_image(image, opt.img_size[0], opt.img_size[1])
print('frame.shape: ', frame.shape)
img = torch.from_numpy(frame).float().unsqueeze(0)
img = img.permute(0, 3, 1, 2)
img = img[:, [2, 1, 0]] / 255.
assert not (opt.device.lower() == 'cpu' and opt.half), '--half only compatible with GPU export, i.e. use --device 0'
model = Yolov5(opt)
if opt.half:
img, model = img.half(), model.half()
model.train() if opt.train else model.eval()
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6 compatbility
if isinstance(m, models.common.Conv):
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
elif isinstance(m, models.yolo.Detect):
m.inplace = opt.inplace
m.onnx_dynamic = opt.dynamic
for _ in range(2):
y = model(img)
print(f"\n{colorstr('PyTorch:')} starting from {opt.weights} ({file_size(opt.weights):.1f} MB)")
if 'onnx' in opt.include:
prefix = colorstr('ONNX:')
try:
import onnx
print(f'{prefix} starting export with onnx {onnx.__version__}...')
f = opt.weights.replace('.pt', 'fix.onnx') if not opt.dynamic else opt.weights.replace('.pt', '_dynamic.onnx')
dynamic_axes = {'input': {0: 'batch'},
'boxes': {0: 'batch'},
'confs': {0: 'batch'}}
torch.onnx.export(model, img, f, verbose=True, opset_version=opt.opset_version,
training=torch.onnx.TrainingMode.TRAINING if opt.train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=True, export_params=True, operator_export_type=torch.onnx.OperatorExportTypes.ONNX,
input_names=['input'],
output_names=['boxes', 'confs'],
dynamic_axes=dynamic_axes if opt.dynamic else None)
model_onnx = onnx.load(f)
onnx.checker.check_model(model_onnx)
import onnxoptimizer
print("Beginning ONNX model path optimization")
all_passes = onnxoptimizer.get_available_passes()
passes = ["extract_constant_to initializer", "eliminate_unused_initializer", "fuse_bn_into_conv"]
assert all(p in all_passes for p in passes)
model_onnx = onnoptimizer.optimize(model_onnx, passes)
print("Completed ONNX model path optimization")
if opt.simplify:
try:
check_requirements(['onnx-simplifier'])
import onnxsim
print(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=opt.dynamic,
input_shapes={'input': list(img.shape)} if opt.dynamic else None
)
assert check, 'assert check failed'
model_onnx = remove_initializer_from_input(model_onnx)
onnx.save(model_onnx, f)
except Exception as e:
print(f'{prefix} simplifier failure: {e}')
print(f'{prefix} export success, saved as {f} ({file_size(f):.1f} MB)')
except Exception as e:
print(f'{prefix} export failure: {e}')
print(e)
print(f'\nExport complete ({time.time() - t:.2f}s). Visualize with https://github.com/lutzroeder/netron.')
import onnxruntime
import numpy as np
ort_session = onnxruntime.InferenceSession(f)
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(img)}
onnx_out = ort_session.run(None, ort_inputs)
torch_out = model(img)
import ipdb
ipdb.set_trace()
np.testing.assert_allclose(to_numpy(torch_out[0]), onnx_out[0], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
np.testing.assert_allclose(to_numpy(torch_out[1]), onnx_out[1], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")在yolov5项目根目录中,使用以下命令导出onnx模型:
python models/export.py --weights yolov5s.pt --img-size 640 \
--batch-size 1 --device 0 --include onnx --inplace --dynamic \
--simplify --opset-version 11 --img test_img/1.jpg其中参数:
weights指定pytorch权重路径
img-size指定图片输入尺寸,以上程序中,固定了输入维度为640,640,所以这个参数并不起作用,可以修改代码中的opt.img_size = (640, 640)部分
--dynamic,允许输入维度可变,以上提供的代码中,只有batchsize维度可变,如果需要height和width都可变,可将dynamic_axes修改如下:
dynamic_axes = {'input': {0: 'batch', 2: 'height', 3: 'width'}, 'boxes': {0: 'batch'}, 'confs': {0: 'batch'}}--simplify简化onnx模型,去掉梯度、优化器等推理中不需要的部分
opset-version, 算法版本,目前11支持比较完善
img, 指定一张测试使用的图片
执行完导出命令后,会在pt权重文件对应的目录下,得到一个onnx模型。
onnx->TensorRT & TensorRT inference
编译C++代码
clone yolov5_trt代码到本地,
cd yolov5_trt
mkdir build
cd build
cmake ..
make -j 10完成编译代码
自定义yaml配置文件
进入到data目录中,新建一个自己的数据目录,copy person目录中的yaml配置文件到自己目录中,修改其中内容:
# 以下所有与路径相关的配置文件的根目录, 左斜杠结尾
path: "../data/person/"
# 模型文件路径,trt若不存在,会使用onnx生成对应trt
model:
onnx: "person.onnx"
tensorrt: "person.trt"
# 输入测试图片,与结果保存路径
image:
input: "person.jpg"
output: "person_result.jpg"
# 输出类别,names文件路径
args:
n_classes: 1
names: "person.names"
# yolov5输入图片尺寸
channels: 3
height: 640
width: 640
# 如果需要dynamic支持,需要配置下面:三个尺寸,最小,opt,最大,开启ifdynamic为1,否则为0
ifdynamic: 1
min: [1, 3, 640, 640]
opt: [1, 3, 640, 640]
max: [1, 3, 640, 640]
# 运行参数, demo运行测试,若trt不存在,会使用onnx默认生成fp32模型
# fp16表示使用fp16生成模型,int8同理, 取值{0, 1}
build:
demo: 1
fp16: 1
int8: 0
# 工作空间大小,单位M,暂时不支持修改
workspace: 4
# nms 插件配置
nms:
topK: 512
keepTopK: 100
# 以下nms相关参数,暂时不支持修改,使用下面列出的默认配置
clipBoxes: 0
iouThreshold: 0.25
scoreThreshold: 0.45
isNormalized: false
output: ["num_detections", "nmsed_boxes", "nmsed_scores", "nmsed_classes"]yaml中注释足够详细,简单说下用法,以需要检测person为例:
- 在data中,新建person目录(随便命名),复制yaml到person目录, 其中,yaml中的 path: "../data/person/" 路径中person为自己命名的路径名字;
- 为检测标签新建一个names文件,命名为person.names, 并修改yaml中args.names项为对应名字
- onnx文件同上
- 其他设置参见yaml中的注释
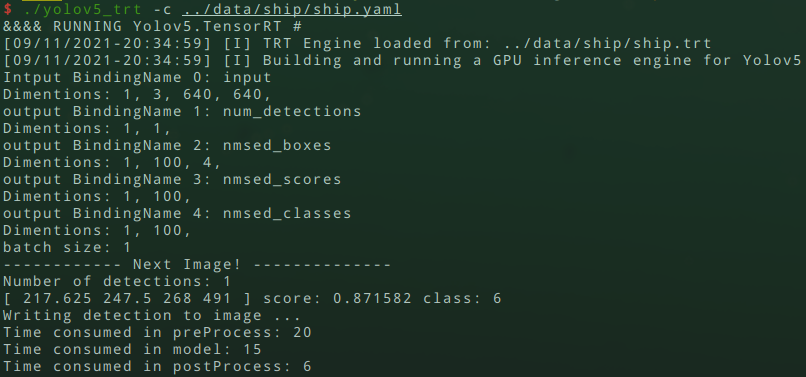
运行代码
进入到build文件夹中,执行:
./yolov5_trt -c ../data/person/person.yaml最后参数为指定yaml配置文件的路径,即可
检测结果如下: